Random bits compression is hard
How well can we compress random byte sequence where every bit have probability p of being set?
import randomdef random_bytes(count, p):bit_string = ''.join(['1' if random.random() < p else '0' for _ in range(8 * count)])return bytes([int(bit_string[8*b:8*(b+1)], 2) for b in range(0, count)])
In theory, for such simple generation procedure 8*count * (p*log(1/p) + q*log(1/q)), q=1-p bits is necessary and enough to encode byte sequence.
Let’s look how well zstd can cope with this data:
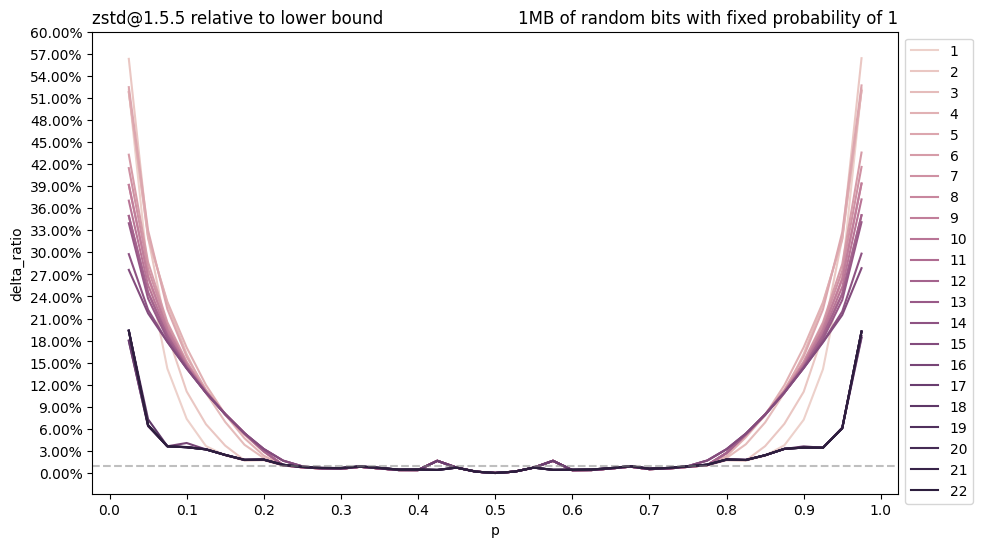
Overall, zstd managed to reach compression size almost equal to the theoretical lower bound (which is not surprising, actually) for 0.25 <= p <= 0.75. Probability values outside of this range corresponds to very specific data which we rarely see in the real life. But still, this is interesting to understand, whats happening on this graph.
-
We can see spike around the values
p=0.425whenzstdrefuses to compress data at all and just leave our binary file as-is. This behaviour is consistent for all levels except 18 and 19 (and also all--ultralevels 20-22) which actually managed to capture dependencies even in this almost random binary file.If we will open
zstdcodebase we can find file clevels.h which defines crucial parameters for compressor for different levels and input file sizes. We can see that levels 17 and 18 differs insearchLog,minMatchandstrategyparameters wherestrategymismatch play crucial role:typedef struct {unsigned windowLog; /**< largest match distance : larger == more compression, more memory needed during decompression */unsigned chainLog; /**< fully searched segment : larger == more compression, slower, more memory (useless for fast) */unsigned hashLog; /**< dispatch table : larger == faster, more memory */unsigned searchLog; /**< nb of searches : larger == more compression, slower */unsigned minMatch; /**< match length searched : larger == faster decompression, sometimes less compression */unsigned targetLength; /**< acceptable match size for optimal parser (only) : larger == more compression, slower */ZSTD_strategy strategy; /**< see ZSTD_strategy definition above */} ZSTD_compressionParameters;static const ZSTD_compressionParameters ZSTD_defaultCParameters[4][ZSTD_MAX_CLEVEL+1] = {{ /* "default" - for any srcSize > 256 KB *//* W, C, H, S, L, TL, strat */...{ 23, 23, 22, 5, 4, 64, ZSTD_btopt }, /* level 17 */{ 23, 23, 22, 6, 3, 64, ZSTD_btultra }, /* level 18 */...},{ /* for srcSize <= 256 KB */ ... },{ /* for srcSize <= 128 KB */ ... },{ /* for srcSize <= 16 KB */ ... }};